The journey of machine learning algorithms
Author: Inventors quantify - small dreams, Created: 2017-02-25 09:37:02, Updated:The journey of machine learning algorithms
In this article, we're going to look at some of the problems that we need to solve in machine learning.http://machinelearningmastery.com/practical-machine-learning-problems/)之后,我们可以思考一下我们需要收集什么数据以及我们可以用什么算法。本文我们会过一遍最流行的机器学习算法,大致了解哪些方法可用,很有帮助。There are many algorithms in the field of machine learning, and then there are many extensions of each algorithm, so it is difficult to determine how to find the right one for a particular problem. In this article, I want to give you two ways to summarize the algorithms that you will encounter in real life.
- ### How to learn
Depending on how they process experience, environment, or whatever we call input data, algorithms fall into different categories. Machine learning and AI textbooks often consider how the algorithm can be adapted to learn.
Only a few major learning styles or learning models are discussed here, and there are a few basic examples. This method of classification or organization is good because it forces you to think about the role of input data and the process of model preparation, and then choose an algorithm that best suits your problem to get the best results.
Supervised learning: The input data is called training data and has known outcomes or is marked. For example, whether an email is spam, or the price of a stock over a period of time. The model makes a prediction, which is corrected if it is wrong, and this process continues until it meets certain correct standards for the training data. Problem examples include classification and regression problems. Unsupervised learning: The input data is unlabeled and has no definite outcome. The model is an induction of the structure and numerical values of the data. Problem examples include association rule learning and clustering problems, and algorithmic examples include the Apriori algorithm and the K-mean algorithm. Semi-supervised learning: input data is a mixture of labeled and unlabeled data. There are some prediction problems but the model must also learn the structure and composition of the data. Problem examples include classification and regression problems, and algorithmic examples are essentially extensions of unsupervised learning algorithms. Enhanced learning: Input data can stimulate the model and cause the model to react. Feedback is obtained not only from the process of supervised learning, but also from rewards or punishments in the environment. Problem examples are robotic control, algorithmic examples include Q-learning and Temporal difference learning.
When integrating data to simulate business decisions, most use both supervised and unsupervised learning approaches. The next hot topic is semi-supervised learning, such as image classification problems, which have a large database of problems, but only a small portion of the images are marked.
- ### Algorithmic similarity
Algorithms are basically classified by function or form. For example, tree-based algorithms, neural network algorithms. This is a useful way to classify, but it is not perfect. Because many algorithms can be easily divided into two categories, such as Learning Vector Quantization, which is both a neural network class algorithm and an instance-based method.
In this section I have listed the algorithms that I think are the most intuitive way to classify. I don't have an endless list of algorithms or classification methods, but I thought it would be helpful to give the reader an overview. If you know something I didn't list, please leave a comment. Let's start now!
- #### Regression
Regression (also called regression analysis) is concerned with the relationship between variables. It applies statistical methods, examples of several algorithms include:
Ordinary Least Squares Logistic Regression Stepwise Regression Multivariate Adaptive Regression Splines (MARS) Locally Estimated Scatterplot Smoothing (LOESS)
- #### Instance-based Methods
Instance-based learning simulates a decision problem in which the instances or examples used are very important to the model. This approach builds a database of existing data and adds new data to it, then uses a similarity measurement method to find the best match in the database and make a prediction. For this reason, this method is also known as the winner-take-all method and the memory-based method.
k-Nearest Neighbour (kNN) Learning Vector Quantization (LVQ) Self-Organizing Map (SOM)
- #### Regularization Methods
It is an extension of other methods (usually regression methods), which are more favorable to simpler models and are better at summing up. I list it here because it is popular and powerful.
Ridge Regression Least Absolute Shrinkage and Selection Operator (LASSO) Elastic Net
- #### Decision Tree Learning
Decision tree methods build a model of decision-making based on actual values in the data. Decision trees are used to solve problems of induction and regression.
Classification and Regression Tree (CART) Iterative Dichotomiser 3 (ID3) C4.5 Chi-squared Automatic Interaction Detection (CHAID) Decision Stump Random Forest Multivariate Adaptive Regression Splines (MARS) Gradient Boosting Machines (GBM)
- #### Bayesian
The Bayesian method is a method of solving classification and regression problems using Bayesian theorems.
Naive Bayes Averaged One-Dependence Estimators (AODE) Bayesian Belief Network (BBN)
- #### Kernel Methods
The most well-known of the Kernel Methods is Support Vector Machines. This method maps input data to higher dimensions, making some classification and regression problems easier to model.
Support Vector Machines (SVM) Radial Basis Function (RBF) Linear Discriminate Analysis (LDA)
- #### Clustering Methods
Clustering, in itself, describes problems and methods. Clustering methods are usually classified by modeling methods. All clustering methods are organized using a uniform data structure to organize data so that each group has the most in common.
K-Means Expectation Maximisation (EM)
- #### Association Rule Learning
Association rule learning is a method of extracting rules from data that can be used to discover connections between large quantities of multidimensional spatial data that can be used by organizations.
Apriori algorithm Eclat algorithm
- #### Artificial Neural Networks
Artificial Neural Networks are inspired by the structure and function of biological neural networks. They belong to the category of pattern matching, and are often used for regression and classification problems, but there are hundreds of algorithms and variation compositions.
Perceptron Back-Propagation Hopfield Network Self-Organizing Map (SOM) Learning Vector Quantization (LVQ)
- #### Deep Learning
Deep learning is a modern update of artificial neural networks. Compared to traditional neural networks, it has a much more complex network structure, many methods are concerned with semi-supervised learning.
Restricted Boltzmann Machine (RBM) Deep Belief Networks (DBN) Convolutional Network Stacked Auto-encoders
- #### Dimensionality Reduction
Dimensionality reduction, like the clustering method, pursues and exploits a unified structure in the data, but it does not use as much information to abstract and describe the data. This is useful for visualizing or simplifying data.
Principal Component Analysis (PCA) Partial Least Squares Regression (PLS) Sammon Mapping Multidimensional Scaling (MDS) Projection Pursuit
- #### Ensemble Methods
Ensemble methods consist of many small models, which are trained independently, make independent conclusions, and finally form a general prediction. Much research focuses on what models are used and how these models are combined. This is a very powerful and popular technique.
Boosting Bootstrapped Aggregation (Bagging) AdaBoost Stacked Generalization (blending) Gradient Boosting Machines (GBM) Random Forest
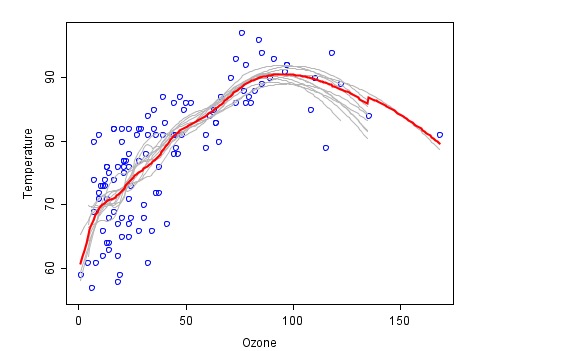
This is an example of a fit using a combination method (from wiki), where each fire code is shown in gray, and the final prediction of the final synthesis is shown in red.
- #### Other resources
This tour of machine learning algorithms aims to give you an overview of what algorithms exist and some of the tools associated with them.
Below are some other resources, but don't feel overwhelmed, the more algorithms you learn, the better it will be for you, but it will be useful to have a deeper understanding of some of them.
- List of Machine Learning Algorithms: This is a resource on the wiki, and while it's complete, I don't think the classification is very good.
- Machine Learning Algorithms Category: This is also a wiki resource, slightly better than the above, sorted alphabetically.
- CRAN Task View: Machine Learning & Statistical Learning: R language extension for machine learning algorithms, see if you understand what others are using better.
- Top 10 Algorithms in Data Mining: This is a published article, now a book, that includes the most popular data mining algorithms.
Translated from Bellow Column/Big Flight Python developer
- Trading strategies of gamblers
- HttpQuery is not used in Python
- What does it mean to be a "dispossessed" hedge fund?
- Talking about the odds of winning and losing
- This is probably the biggest lie in investing!
- How to Survive in a Random World
- Discover trends and follow trends
- Disclosure of the Big Data Fund
- Why are retail investors buying and selling (Contrarian)?
- If you can't win, throw a coin and make a deal, can you still make money?
- When we predict probabilities, what do we predict?
- Programmatic transaction flow chart (an idea to the program)
- _C() Re-test the function
- _N() function, small number of decimal places, precision control
- Adaptive learning in the first place
- Real and formal trading systems
- Three short stories about understanding real estate, stocks and money
- Six branches of Quant uncovered
- Dynamic time series based pattern recognition strategies
- Thinking about an analog exchange