मूल्य आधारित स्टॉप लॉस और ले लाभ रणनीति
लेखक:चाओझांग, दिनांक: 2023-11-23 15:36:00टैगः
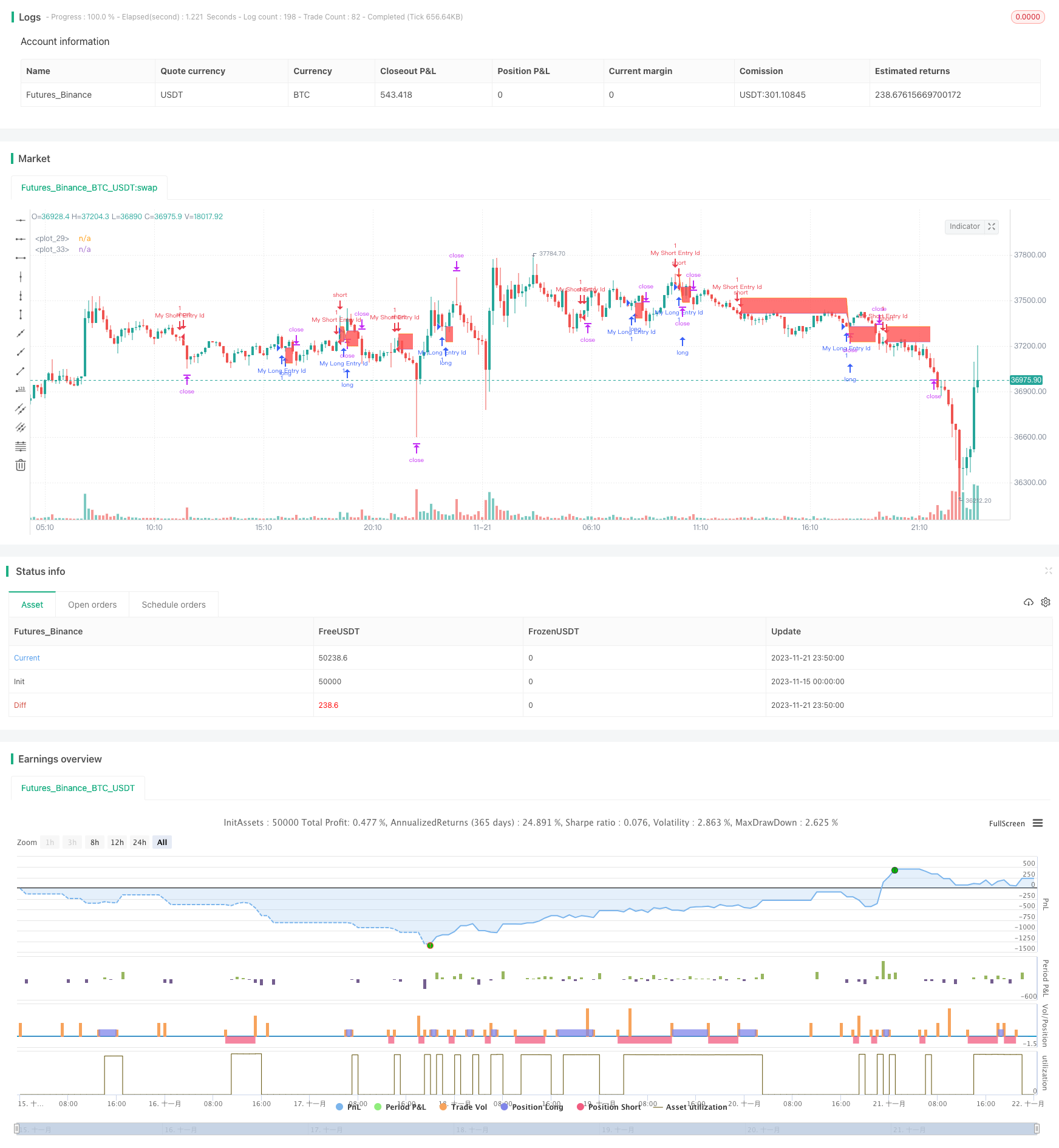
अवलोकन
इस रणनीति का मूल विचार इनपुट स्टॉप लॉस का उपयोग करना है और प्रत्येक व्यापार के जोखिम और लाभ को प्रबंधित करने के लिए उचित स्टॉप लॉस और लाभ टिक स्तर निर्धारित करने के लिए लाभ राशि लेना है।
रणनीति तर्क
रणनीति पहले यादृच्छिक प्रवेश संकेत सेट करती है, जब SMA14 SMA28 के ऊपर से गुजरता है तो लंबी जाती है, और जब SMA14 SMA28 के नीचे से गुजरता है तो छोटी जाती है।
प्रविष्टि के बाद, रणनीति स्टॉप लॉस डॉलर राशि इनपुट के आधार पर स्टॉप लॉस टिक स्तर की गणना करने के लिए moneyToSLPoints फ़ंक्शन का उपयोग करती है। इसी तरह, यह लाभ लेने के टिक स्तर की भी गणना करता है। यह डॉलर की राशि के आधार पर स्टॉप लॉस और लाभ लेने को लागू करता है।
उदाहरण के लिए, यदि 100 अनुबंधों के साथ प्रत्येक टिक की कीमत 10 डॉलर है, और स्टॉप लॉस 100 डॉलर पर सेट किया गया है, तो स्टॉप लॉस टिक का स्तर 100/10/100 = 0.1 टिक के रूप में गणना की जाएगी।
अंत मेंstrategy.exitस्टॉप लॉस और टेक प्रॉफिट एक्जिट पॉइंट्स सेट करने के लिए प्रयोग किया जाता है। स्टॉप लॉस और टेक प्रॉफिट लाइन भी डिबगिंग उद्देश्यों के लिए ग्राफ किए जाते हैं।
लाभ विश्लेषण
इस मूल्य आधारित स्टॉप लॉस और ले लाभ रणनीति का सबसे बड़ा लाभ यह है कि पैरामीटर सहज हैं। पैरामीटर चयन का मार्गदर्शन करने के लिए जोखिम और इनाम के बीच संबंध स्पष्ट रूप से देखा जा सकता है।
इसके अलावा, डॉलर की राशि वाले स्टॉप बाजार में उतार-चढ़ाव के परिवर्तन के समय निश्चित टिक स्टॉप की तुलना में वास्तविक जोखिम जोखिम को बेहतर ढंग से नियंत्रित कर सकते हैं।
जोखिम विश्लेषण
इस स्टॉप लॉस और लाभ लेने की रणनीति के साथ कुछ जोखिम हैंः
-
यदि स्टॉप लॉस बहुत व्यापक है, तो रिवर्स पर पकड़ना आसान है। यदि स्टॉप दूरी बहुत बड़ी है, तो अल्पकालिक रिवर्स की संभावना बन जाती है और व्यापार को पकड़ सकती है।
-
यदि लाभ लेने की दूरी बहुत कम है, तो सामान्य एकतरफा रुझानों के लिए इसे प्राप्त करना मुश्किल होगा, जिससे लाभ की संभावना कम हो जाएगी।
-
उचित अनुबंधों को चुनने की आवश्यकता है। यदि कच्चे तेल जैसे उच्च टिक मूल्य अनुबंध का उपयोग किया जाता है, तो उसी डॉलर स्टॉप लॉस का अनुवाद बहुत कम टिक में होगा, जो आसानी से शोर पर रोक दिया जा सकता है।
अनुकूलन दिशाएँ
इस रणनीति में सुधार करने के कुछ तरीके हैंः
-
समय प्रविष्टियों के लिए प्रवृत्ति, अस्थिरता, मौसमीता आदि को बेहतर ढंग से जोड़कर प्रवेश संकेत को बढ़ाया जा सकता है।
-
विभिन्न उत्पादों के आधार पर उपयुक्त स्टॉप/लाभ प्रतिशत चुने जा सकते हैं। उच्च अस्थिरता वाली वस्तुओं में बड़े स्टॉप का उपयोग किया जा सकता है।
-
स्टॉप अस्थिरता के अनुकूल हो सकते हैं, अस्थिरता बढ़ने पर व्यापक हो सकते हैं और अस्थिरता गिरने पर सख्त हो सकते हैं।
-
विभिन्न ट्रेडिंग सत्रों के लिए अलग-अलग स्टॉप/प्रॉफिट दृष्टिकोणों का उपयोग किया जा सकता है। Whipsaws में पकड़े जाने की संभावना को कम करने के लिए अमेरिकी सत्र के दौरान तंग स्टॉप का उपयोग किया जा सकता है।
निष्कर्ष
यह रणनीति डॉलर की राशि के आधार पर सहज स्टॉप लॉस और ले लाभ को लागू करती है। इसके फायदे सहज मापदंड और पूंजी नियंत्रण हैं। कमियां उलटफेर और खोए हुए लाभ में पकड़े जाने की आसानी हैं। इसे अधिक स्थिर बनाने के लिए प्रविष्टियों को बढ़ाने, स्टॉप / लक्ष्यों को अनुकूलित करने, बेहतर उत्पादों का चयन करने आदि से सुधार किया जा सकता है।
/*backtest
start: 2023-11-15 00:00:00
end: 2023-11-22 00:00:00
period: 10m
basePeriod: 1m
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT"}]
*/
// This source code is subject to the terms of the Mozilla Public License 2.0 at https://mozilla.org/MPL/2.0/
// © adolgov
// @description
//
//@version=4
strategy("Stop loss and Take Profit in $$ example", overlay=true)
// random entry condition
longCondition = crossover(sma(close, 14), sma(close, 28))
if (longCondition)
strategy.entry("My Long Entry Id", strategy.long)
shortCondition = crossunder(sma(close, 14), sma(close, 28))
if (shortCondition)
strategy.entry("My Short Entry Id", strategy.short)
moneyToSLPoints(money) =>
strategy.position_size !=0 ? (money / syminfo.pointvalue / abs(strategy.position_size)) / syminfo.mintick : na
p = moneyToSLPoints(input(200, title = "Take Profit $$"))
l = moneyToSLPoints(input(100, title = "Stop Loss $$"))
strategy.exit("x", profit = p, loss = l)
// debug plots for visualize SL & TP levels
pointsToPrice(pp) =>
na(pp) ? na : strategy.position_avg_price + pp * sign(strategy.position_size) * syminfo.mintick
pp = plot(pointsToPrice(p), style = plot.style_linebr )
lp = plot(pointsToPrice(-l), style = plot.style_linebr )
avg = plot( strategy.position_avg_price, style = plot.style_linebr )
fill(pp, avg, color = color.green)
fill(avg, lp, color = color.red)
- बोलिंगर बैंड्स रणनीति के बाद ब्रेकआउट अल्पकालिक प्रवृत्ति
- लाभ लेने और स्टॉप लॉस के साथ डुप खरीदना
- आरएसआई अक्षीय चलती औसत क्रॉसओवर रणनीति
- दोहरी एसएमए क्रॉसओवर रणनीति
- दोहरी ईएमए और आरएसआई संयोजन रणनीति
- अनुमान खाड़ीः एसएआर के आधार पर ट्रेंड फॉलो रणनीति
- मूविंग एवरेज पर आधारित मूल आदिम ट्रेंड ट्रैकिंग रणनीति
- बोलिंगर बैंड्स स्टॉप लॉस रणनीति
- बहु-सूचक पर आधारित रुझान ट्रैकिंग रणनीति
- एकाधिक चलती औसत गतिशील प्रवृत्ति रणनीति
- समय-सीमा बिजली व्यापार रणनीति
- द्विदिशात्मक ट्रेंड ट्रैकिंग मूविंग एवरेज क्रॉसओवर रणनीति
- व्यक्तिगत गति व्यापार रणनीति
- रणनीति का पालन करते हुए चलती औसत लिफाफा चैनल की प्रवृत्ति
- ट्रेंड जजमेंट के साथ संयुक्त गतिशीलता बहु-कारक मात्रात्मक ट्रेडिंग रणनीति
- आंतरिक आयाम स्टॉप लॉस पर आधारित गति ब्रेकआउट रणनीति
- गोल्डन क्रॉस पर आधारित ट्रेंड ट्रेडिंग रणनीति
- चैनल ब्रेकआउट के आधार पर ट्रेंड ट्रैकिंग रणनीति
- पिरामिडिंग के साथ बोलिंगर ब्रेक आउट रणनीति
- गति का पता लगाने की रणनीति